
Our Moment: We Asked the Wrong Question About Data
And Why Ownership Isn’t Black and White

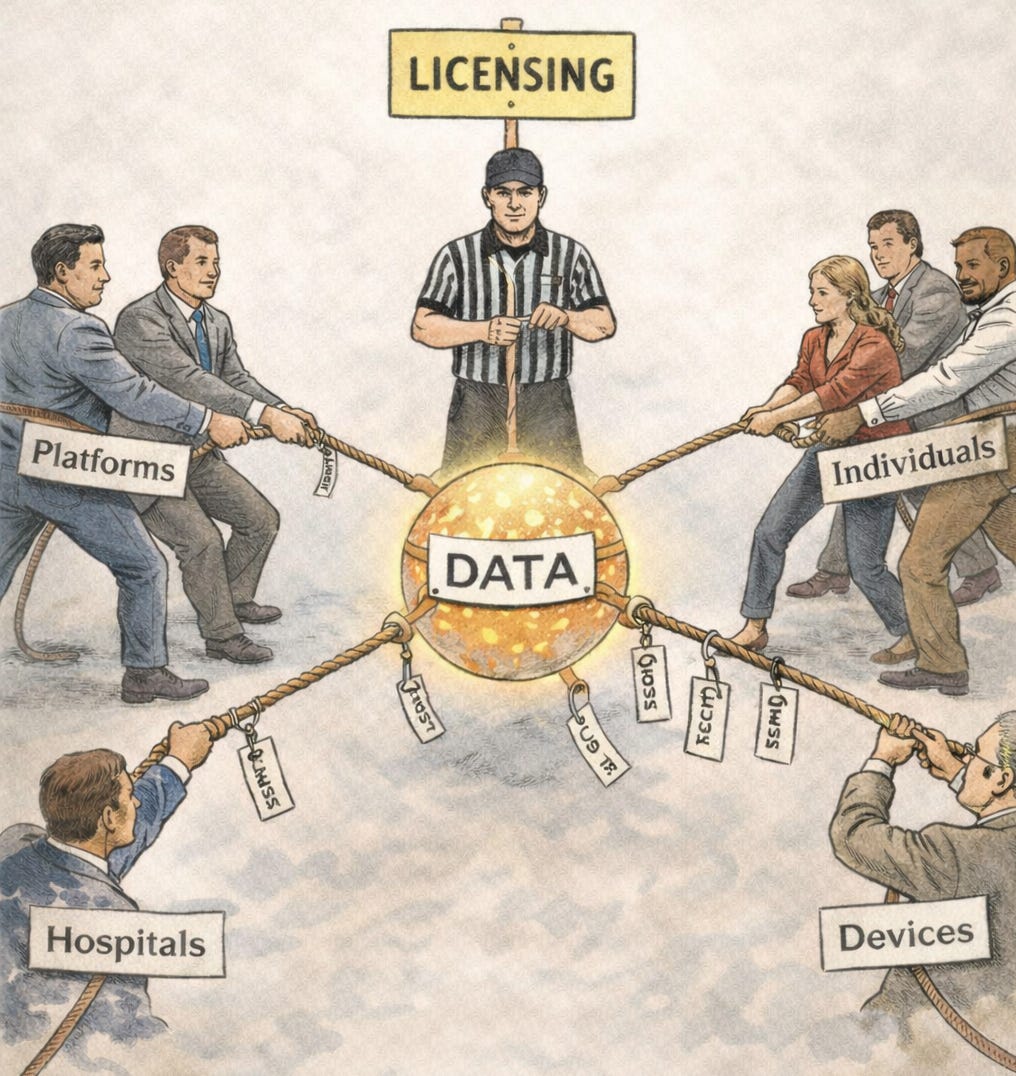
For years the debate around data has centred on one idea: data ownership.
Many people believe they should own their data. They want control over it and a fair share of the value created from it.
The instinct behind this is understandable, but the way we approached the problem may have been wrong.
In many ways, we tried to solve a modern problem using industrial thinking. Data does not behave like physical property, yet much of the debate has treated it as if it does.
That misunderstanding has shaped much of the discussion that followed.
The Data Ownership Mistake
When the idea of data ownership first emerged, many assumed it would function like traditional assets. The thinking was simple: if the data came from you, then you must own it.
In reality, data rarely originates from a single person.
Health data, for example, involves doctors, hospitals, diagnostic systems, devices, and patients. Financial data involves individuals, banks, payment networks, and regulatory systems. Location data emerges from the interaction between phones, infrastructure, services, and users.
Even something as simple as a photograph contains multiple layers of contribution: the person taking it, the people in the image, the device capturing it, and the platform storing or distributing it.
Data is rarely created in isolation. It emerges from interactions.
Ownership Is Not Black and White
Once you recognise this, the central question begins to change. The issue is not simply who owns the data.
The more meaningful question is who has the right to access and use it.
Ownership in the modern world is also not as black and white as we often assume.
Your ideas, creativity, and the insights you generate can be clearly owned as intellectual property.
But the data that helps produce those insights is often created between multiple participants. It emerges from relationships, systems, and shared activity.
In these circumstances, the goal is not strict ownership of the raw data itself. The goal is access to the data that was created, so that individuals and organisations can generate their own insights from it.
Those insights can be owned, licensed, and even shared in value with the participants who contributed to their creation
AI Prompts and Human Insight
The rise of artificial intelligence makes this even clearer.
When someone interacts with an AI system, they provide a prompt. The system then processes that prompt using vast models trained on enormous datasets before generating an output.
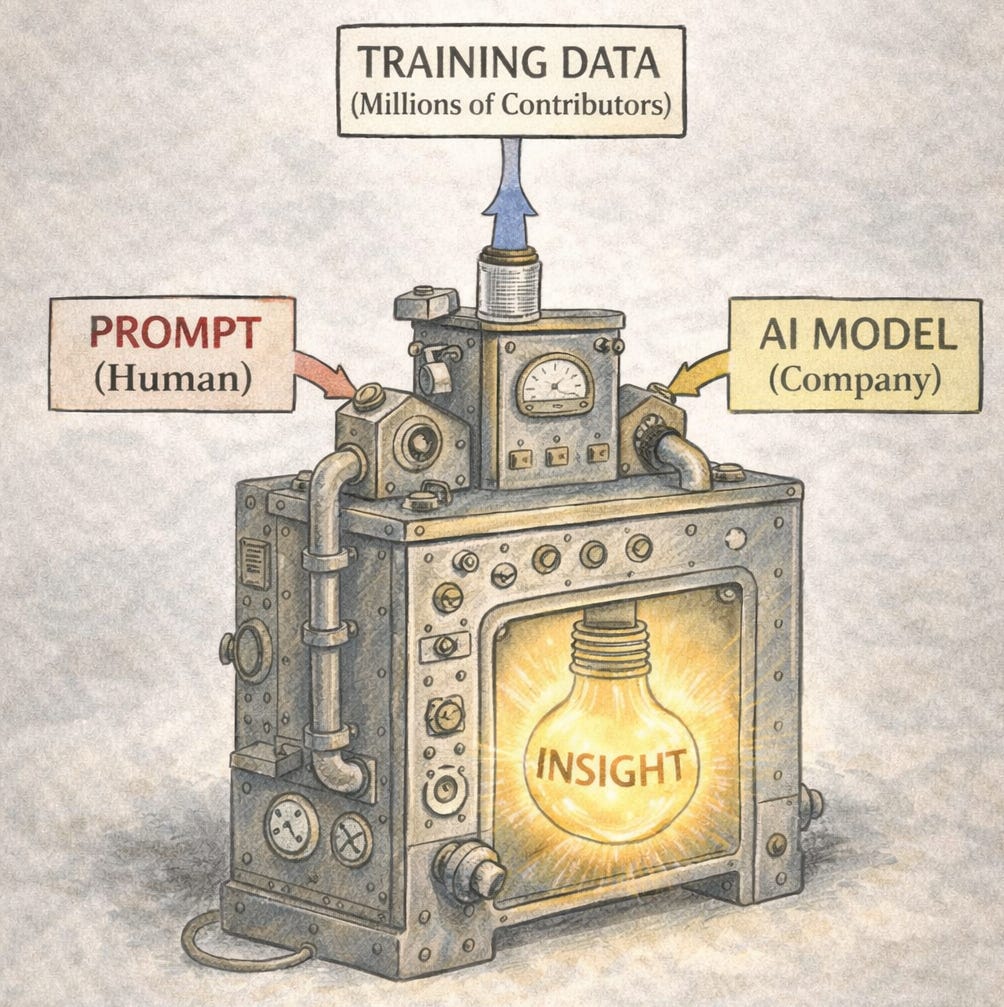
So who owns the result?
The prompt came from a person.
The model came from a company.
The training data came from millions of contributors across the world.
The resulting insight is therefore the product of collaboration between many participants.
This is precisely why simple ownership models struggle in the AI era. Increasingly, value does not come from raw data alone, but from the process through which intelligence is generated from it.
Content and Intellectual Property
The same issue now sits at the centre of the debate around creative work.
Writers, artists, journalists, and publishers are asking a legitimate question: should their work be used to train AI systems without permission?
Their concern is understandable. However, the deeper issue again returns to rights and usage.
Creative work has long been governed through intellectual property systems. These systems never required knowledge to stop flowing. Instead, they created mechanisms that recognised contribution, protected creators, and allowed knowledge to continue circulating through society.
The Hero of the Story: Licensing
In Our Moment I wrote about a different way of thinking about data and contribution.
Rather than forcing data into a traditional ownership model, we may need systems that recognise rights of access and contribution.
This is where licensing becomes important.
Licensing allows data, knowledge, and content to flow while still recognising rights. It separates two ideas that are often confused.
Individuals and organisations can hold rights over the data and contributions they provide. When someone combines data, interprets it, and generates new understanding, that resulting insight can itself be owned as intellectual property.
However, because insight often emerges from the contributions of many participants, licensing frameworks can also ensure that value is recognised and shared where appropriate.
In this way, licensing creates a structure that allows data to be shared and combined while still recognising where contributions originate.
Progress is underway
What is interesting is that we are now beginning to see movement in this direction.
A UK parliamentary committee recently recommended a “licensing-first” approach to AI training, suggesting that companies should obtain permission before using copyrighted material to train their models.
At first glance this may appear to be a dispute between technology companies and the creative industries. In reality, it may signal something much larger.
We may be witnessing the early foundations of systems that govern how knowledge, data, and human contributions move through society.
Importantly, this is no longer just a theoretical idea.
The technology needed to support these systems already exists. Digital identity systems, personal data infrastructures, programmable permissions, and distributed ledgers make it possible to manage access, rights, and usage at scale.
What may be required now is not entirely new technology, but a shift in how we think about data itself.
The Shift Ahead
The world cannot function if data is locked away. Artificial intelligence depends on the ability to combine knowledge from many sources.
At the same time, the world cannot function if the people contributing that data have no rights.
The future may therefore depend on a simple principle: not strict ownership of data itself, but clear rights over how it is accessed, used, and combined.
Licensing may prove to be the mechanism that makes that possible.